The need of clean codebase
When I joined CoinList, it was at the end of a high-growth phase, during which the technical debt had accumulated to enormous levels. People were used to cutting corners everywhere, like someone was running a bash script from their computer every Sunday at 8pm because they did not take the time to automate this specific process.
But then you end up with a full team of 4 engineers constantly on call, fixing fires. Four might not seem a lot, but that was a quarter of the engineering group. A quarter was no longer working on new products. What surprised me is that two years later, nothing has been fixed, and there was still 25% of engineering locked into daily fires. And rightfully, our users were constantly complaining about how poor the product was, with all the problems never truly fixed.
One thing I enjoyed at Shopify is the culture of “building for the long term”. Which means being able to take a step back from time to time in order to make sure everything is in order before pushing for yet another new idea.
I can understand why taking the time to clean up your codebase in a startup is less valuable when the time is ticking and a few extra weeks might be the difference between surviving and not having enough cash to pay your employees. But over time, you get slower, so slow that everything takes as long as a big company, if not more.
This tension between Product Development and Paying the Tech Debt has always been here. Sometimes, only product feature work is seen as able to increase the company’s value, which is what most people want to optimize for.
Nevertheless, there is often a strong inverse correlation between the amount of technical debt a team has created and its capacity to move fast past that.
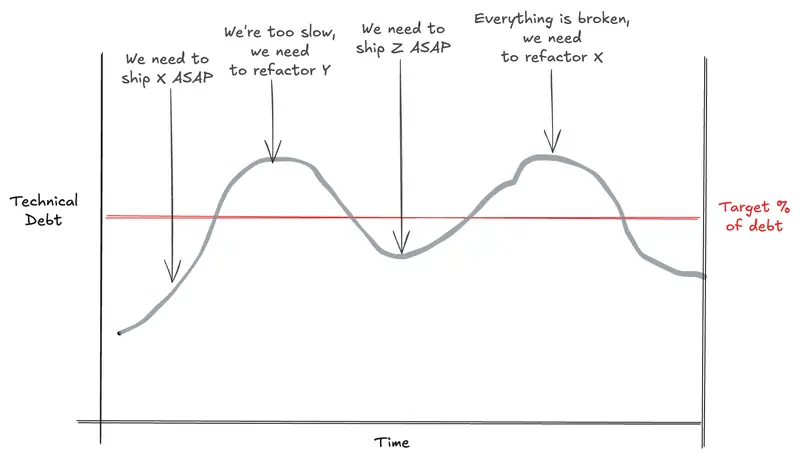
For the ones less familiar, what is technical debt?
In my own words, it is the accumulation of wrong assumptions and bad architecture decisions (skill issues). It is the lack of rules enforcement and coherence.
It is often very visible when someone new is hired. The time it takes to onboard them is correlated with the number of unspoken rules and conventions that are not obvious from the code.
What does it mean in this new era of AI-assisted code? Will tech debt no longer be a thing, and will code become disposable?
If you have ever used LLMs to assist you with coding, I feel like onboarding a new engineer every single time. You should know that you have to send them as much context as possible (to a certain extent). This is why people create markdown files everywhere in the codebase (AGENTS.md, .claude/rules/…, etc.).
This is mostly because those AI models are very knowledgeable but lack the specific context of your use case. This is also why they perform extremely well from 0 to 1 (new projects) but show diminishing returns once the codebase is large and has been around for years.
The problem with those large language models is that it is hard to control what they will assume at first. So any file, any function, any variable is susceptible to being read and taken for granted by the LLM. Then it feels like a constant battle of (re)explaining how to do things and what to assume or not. Ideally, I want them to be smart enough so that I don’t have to watch their back (same with my engineers).
In a perfect setup, the AI model should hold as much historical context as possible. You should start one session and keep using it for various tasks in your repository. This is what an engineer would naturally do in your company. They would learn. This also seems to be what most companies are working on these days: “long-term memory that would improve and supplement the use of large context windows”.
Today, some people claim that AI should write all the code and that quality and consistency no longer matter. Code is now disposable.
While there is some truth to it, I don’t believe it holds over a long period of time. Yes, code can be disposable for testing new ideas, building a prototype, and finding PMF (Product-Market Fit). After that stage, I still don’t believe that’s how reliable or good software should make it into production.
With all of that in mind, I believe it has never been easier or more important to clean up your codebase. Luckily, we now have LLMs that are good at refactoring, especially when it has been partially implemented. “Follow and implement this pattern to the rest of the codebase”. The engineers have to remain the architects of the repositories and be the gatekeepers of how well and how clean those are.
Yet the need to ship new products extremely quickly has increased lately. The expectation is to launch x5, x10, and x100 more products a year. Yet we never experienced as many outages as GitHub, CloudFlare, and others (to name a few). There is this FOMO about what others are doing and the need to catch up. It is real.
Personally, I don’t believe that adding every feature in the world is what makes your product better in the end. Strong product visions are more important than ever. Good products are coherent, reliable, and easy to use.
For example, Linear is a great product that likely has 10x fewer features than Asana, Jira, and other tools. But the quality of their software is high, which makes it a no-brainer for engineers to use.
I am curious to hear from others. Are we going to expect people to care less about the level of tech debt, dead code, and wrong assumptions in the codebase? Or will the end user still want 99.9% bug-free sessions, which would put pressure on the company to keep the bar of quality high?